Data Pipeline
Streaming Data Pipeline with Kafka, Flask, Spark, Hadoop & Presto
Overview
This project is based on the idea of collecting events from a fictional restaurant app. The app allows a user to create a profile, login, search for menus and then order them from restaurants who will deliver them. The goal of the work is to demonstrate a data pipeline in docker using open source systems such as kafka, spark, hadoop and presto. The GitHub link has all files and setup instructions.
This analysis looks at user adoption with the goal of improving use of the app by examining
- When people login and use the app
- What kind of menus they search for
- What kinds of food are ordered
- What kinds of reviews are given
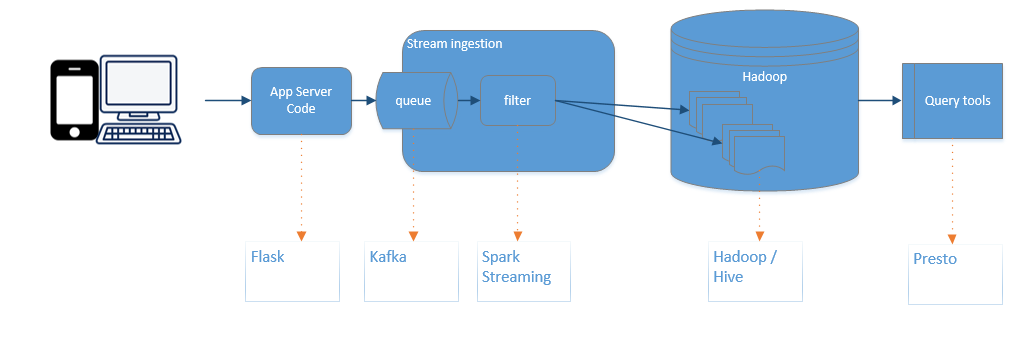
The data pipeline uses the following tools:
- kafka to store topics
- flask to run a python web app (restaurant_api.py)
- bench to generate ~42,000 events
- spark streaming to read the events and store in hive
- hadoop (cloudera) as the distributed storage
- hive to store the table schemas
- presto to run queries
The goal is to represent something approaching large volumes of usage. It takes approximately 5 minutes to generate ~42,000 events using Bench, running on a 2 VCPU server with 3.25 GB of memory.
Code available on GitHub
An example of report with SQL is included in the repo Report